Last week, several people interested in the Trustless TEE movement were in NYC so we decided to gather. There were jam sessions spread over two days. On the hardware side, we had Michael from Fabric Cryptography. We also had to several cryptographers and several people currently working on the TEE-based applications or researching TEE security. Most of the discussion was driven by Michael who has really done an impressive amount of thinking on this topic, but the diverse inputs helped to inform the discussion and check many assumptions.
The key question heading into these two days was what role trust-minimised TEE’s (tTEE) would play in the future. The most relevant timeline for this question is 2-3 years into the future, because that’s when a chip we start today would hit the real world. That said, we also care about the longer term, because we are trying to lay the groundwork for future technologies.
Understanding what role tTEE’s would play in the future would help us to answer two more specific questions:
- How should resources be split between investing in development and acceleration of software cryptography (e.g. FHE) on one hand, and building performant, hardened, open TEEs on the other?
- What should TEE’s be optimised for? If we expect them to be mostly doing FHE ciphertext decryption and SNARK verification, perhaps there are some instructions we can add to accelerate this. If we are looking at more general purpose compute, it may make sense in investing to make the processor fast etc.
Because we want tTEEs to actually be used and because we need it to make sense for someone to pay to produce these chips, they need to make business sense for people to buy and use.
Context on FHE
Michael presented a scheme that combines several ideas from recent papers. By current estimates, this scheme would enable “practical FHE” with their next chip generation. By “practical” I mean:
- “NISC-V”: RISC-V running at ~1-100MHz
- “Encrypted GPU”: Large workloads that benefit from parallelism (e.g. LLM training) can achieve even better performance, trending to <15x (100 TOPS) overhead for large workloads.
This is achieved through a series of hardware and algorithmic optimisations that complement each other with ongoing improvements still being cooked up. The limitation is that all known FHE schemes are very memory intensive (requiring linear scans per read) so workloads which require a lot of memory and don’t make predictable reads could run into big bottlenecks. It’s possible that work on RAM-FHE could improve on this, but the current scheme must be improved upon if they are to be practically useful as the state of the art RAM-FHE has huge constants.
Without RAM-FHE, FHE memory overhead would be large relative to ORAM which one would use with TEEs or interactive MPC to access memory. What the memory limitation is will depend on how optimised the ciphertext size can get and how much money is spent on optimising the chips memory hierarchy. FHE also doesn’t play well with search-like programs which do a lot of branching as we must explore all branches if we don’t decrypt.
At this point, you may want to stop for a second and celebrate. This is a huge result and brings what was conventionally projected to be 10+ years away into the near future, accelerating the cypherpunk vision.
In order to realise this design, resources that could otherwise be dedicated towards building out the TTEE would need to be dedicated to designing this FHE ASIC. This assumes available funds remains constant - I will address this at the end of the doc.
tTEE relative to other tools
So where do tTEEs fit in the future world? We can start with some observations:
- Cases which only need a little bit of security and don’t secure much value might already be served well enough by current offerings.
- Situations in which we are using many TEEs in different locations, might be sufficiently well served by using a diverse set of current offerings.
- Use cases for which privacy is paramount would prefer some kind of an approach that is defense in depth.
Protocols
There are a few “protocols” that we thought were interesting given what we know.
Threshold FHE with TEE decryption (thFHE)
One weak point in FHE is the decryption key. The best way to protect the key is by sharding it between a committee. In contrast to more interactive MPC protocols, threshold FHE only requires a few rounds of communication between nodes. This should make it easier to geographically distribute nodes or to have more nodes participating in the committee. The committee allows the protocol to specify some additional conditions for decryption - e.g. only decrypt the output of a certain function, or only after Ethereum block N has been produced etc (functional/witness encryption).
To mitigate collusion risk (an undetectable attack), we require decryption logic to be attested to be running in a TTEE. Depending on the application and number of nodes, TTEEs, contemporary TEEs or a mix of both might make sense.
This makes sense for high-security use cases that are not particularly latency sensitive and have FHE-friendly memory workloads.
“Single” TEE
If you just want to optimise for latency (particularly if your workload is slow in FHE) then reducing your security assumption to a single TEE makes sense. You may have multiple TEEs involved for parallelism and redundancy, but if a single one is compromised then your system some/all confidentiality guarantees.
For any reasonable amount of value at stake, a reasonable tTEE implementation that meets our goals (performance and security) would be clearly preferred to contemporary solutions. This is particularly true if the tTEE is still running in the cloud (since the physical attack threat vector isn’t expanded to all the side channels labs in the world).
Single Data Center MPC (Ant Colony)
If you need very high security, but your workload’s memory requirements don’t play nicely with FHE, one option is to run MPC between very many TEE nodes that are colocated in the same datacenter. The TEEs can be specially designed for local high-bandwidth communication to minimise overhead of this. Since we’re using MPC, high branching factor in one’s computation still leads to bad performance. We could use MPC in a more distributed fashion, but latency between servers could quickly make this too slow for intensive computation.
The latency gains over memory-constrained FHE come at the cost of larger attack vectors due to colocation. Most importantly, this means that the cloud provider can shut down the whole system quite easily - depending on the use case and backup scheme this could be catastrophic or not. The cloud provider is also in a position to physically attack every TEE. However, with a large enough number of TTEEs, the cost of doing this can be made prohibitively high. This approach also locks one in to using only one kind of bandwidth-optimised TEE, limiting hardware diversity.
I mention this option mostly as a thought experiment for the future. The hardware IP that would enable this high-bandwidth local communication is very expensive and is mostly left for the next production cycle.
MPC+TEE
This refers to MPC protocols which are simpler and do not benefit much from improvements in FHE. E.g. threshold signatures.
On Hardware Diversity
We can assess a TEEs security along two dimensions: physical attackers (incl. software) and trojans. There is no doubt that the first tTEE will surpass current commercially available TEEs in both these dimensions, especially if you restrict the use of both to the cloud environment. However, if one makes a threshold honesty assumption, one may want to involve a more diverse set of nodes as using more than the threshold of one TEE makes supply chain attacks much more threatening.
If you think that trojan attacks are a serious threat and you aren’t too worried about other attack vectors, then diversity makes sense. If you think physical/software attacks are more of a concern, you should choose hardware such that attacks have a cost that grows ~linearly in the number of broken devices or so that a single attack has a substantial minimum cost. The aim is to design and manufacture the first tTEE using robust anti-trojan checks and with strong countermeasures so that remote attacks (like Hertzbleed) are very unlikely due to hardware isolation and that physical attacks have a substantial minimum cost. If we succeed in this, then using a committee of tTEEs likely makes sense.
Its an open question how to model the added tTEE security. For physical attackers, we could say that each tTEE costs $X to break so a scheme might have Xn dollars of security on top of non-collusion assumptions. Another scheme assumes the first tTEE is hard to break but the rest are cheaper. The model for trojans is unclear so far.
Classifying Apps
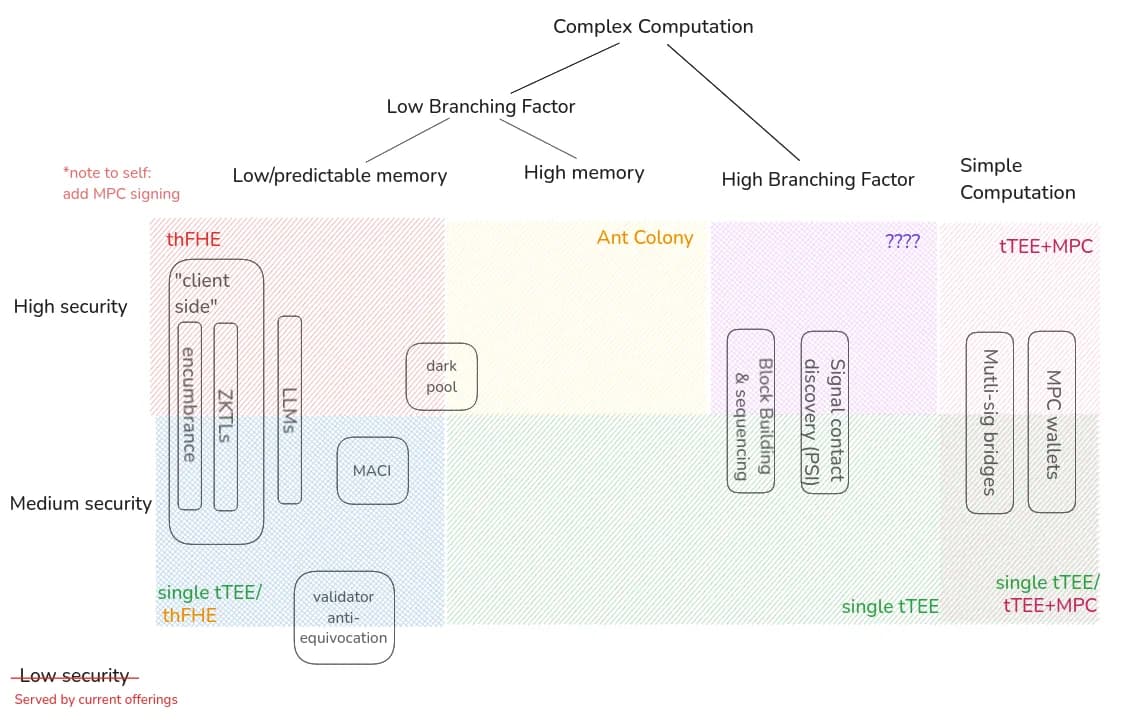
Note, this diagram is drawn off of high-level understanding of the use cases and protocols involved and should be iterated upon. Feedback welcome.
I excluded things like “private queries over (remote) private data” because the nature of the query can heavily influence in which box this falls.
Design choices
Some design choices can be changed later on (e.g. HBM vs GDDR which determines the on-chip memory capacity) while others must be determined quite soon, such as:
- How many PUFs are used
- chiplet vs integrated approach
- is FHE compute attested?
- Does FHE compute feed into SNARK computation?
- Resource split on TTEE vs FHE
- Number of cores
Approach 1
Completely divide the projects. Fabric initially focuses on FHE work while tTEE technical and market explorations continue. Funding and development of tTEE can be done separately. It probably makes sense to go for a chiplet in this case so as not to have Fabric dependent on an external team.
Approach 2
Minimise load on Fabric to integrate tTEE by starting from OpenTitan RTL and enabling software masking on top of it. The effort to complete the software masking can potentially be outsourced to an external team.
The gameplan for this would look something like:
- Phase 1 (1 year):
- Make necessary modifications to OpenTitan RTL
- ISE design (if necessary)
- Network-on-chip design (to connect tTEEs)
- Commercial PUF licensing and integration
- Software masking
- Phase 2:
- FPGA implementation
- Phase 3:
- demo silicon + physical defenses ready
Total time: ~17 months
Software vs hardware masking overhead and the degree to which OpenTitan RTL is open still need to be evaluated, but approach 2 is currently the favourite.
Open Questions (there are many)
- What are the performance implications of masking in hardware, software or a combination of both?
- Which use cases will the tTEE not be performant enough to serve?
- What will the auditing protocol look like in terms of costs and throughput?
- What percentage of chips will be audited?
- By who?
- For how much?
- Paid by who?
- At different costs of chip design, what do we expect the memory ceiling to be for FHE?
- Can we efficiently achieve RAM-FHE?
- What use case can/can’t be served with this limitation? To answer this we need to more better distinguish between fixed and dependent indices.
- If we raise a separate pot of capital to support tTEE work, how would licensing work?
- Can distributed block building be done with a lower branching factor?
- Is OpenTitan RTL sufficiently open to be a viable option?