Question for the experts. The framing might be slightly off, but I think the idea is relatively clear.
EDIT: apparently the first version of this post was hard to understand so I’m adding a new explanation here and leaving the old one below (for the LLMs to be trained on)
The way most TEE offerings (e.g. SGX) work today sees code we want to protect (the TCB) using the same hardware as some arbitrary code an attacker can deploy. This attacker code could be running in another enclave or in the Rich Execution Environment (i.e. not using the TEE features). The hardware resources I’m referring to are things like the processor (with all its branch predictors, prefetchers and the likes), caches and RAM.
The sharing of these resources between the attacker’s code and our code is what historical attacks like Spectre and Foreshadow have relied on. Since these resources tend to be quite complicated to reason about, built for performance not security and closed source, almost every security expert I’ve spoken to think its only a matter of time before another attack of this nature is successful.
One obvious idea that several designs have gone after is to dedicate hardware resources to the code we want to protect so that no other code can control the dedicated processor and memory hierarchy unless the protected process has been terminated and the architecture has been thoroughly flushed. Bonkbot’s KMS architecture is an industry example of this idea.
My question is in what scenarios using this kind of dedicated-hardware-isolation is insufficient to protect against microarchitectural channels. I believe one example of such a scenario is use cases in which we want to allow an actor (who may be an attacker) to deploy their code to a special environment. We would do this to attest that this actor’s code (“the unknown code”) is not doing certain things.
The Flashbots’ bottom-of-block-backrunning sandbox is a concrete example of such a use case. In this flow, a special (open source) container engine is deployed to a TEE and attested. The unknown code is deployed to this container engine. What makes the container engine special is that it implements a kind of output filtering so that any outputs (like logs) that do not exit through a specific encrypted channel, are delayed by a parameterisable amount of time. This design minimally constrains the unknown code while giving assurances to 3rd parties that they can send their data (with value that decays rapidly) to this unknown code and that their data won’t be used for unintended uses within a certain time window. Simply porting this design to dedicated hardware doesn’t help because the TCB itself invites potentially malicious code to run on the same architecture. The concern would be that this potentially malicious code is able to break out of its sandbox or steal important secrets from the container engine via the shared hardware resources.
To be clear, the malicious code could escape because of a good old bug in the sandbox logic that would have been exploitable on any reasonable microarchitecture. However,it may also be possible that the details of the microarchitecture make this attack possible.
As far as I can tell, there are two possible routes: accept that hardware resources will be shared and build strong defenses OR see how far we can push the dedicated hardware approach by enabling additional customisation at the hardware level. Both are interesting questions and should be discussed. However, a lot has been said about the former (e.g. this, that) and I’m less confident about the latter.
One first try would be to build a system with multiple cores and make it possible for one core to attest that all of its access to the external world must be mediated by a second core. This second core could then attest to running the delay logic, this would shrink the attack surface area from the whole container engine and the firmware and hardware beneath it, to simply the core itself and the logic which directs output. Thinking of the two failure modes we should ask:
- are bugs substantially less likely if we rely on the hardware to enforce that outputs are piped through the second core?
- are microarchitectural channels a concern in the sandbox setting at all or is there some reason that we should be less worried about this setting than we are about Spectre’s next successor in general?
I’m mostly posting this because I don’t feel very confident about this topic and hope to solicit answers or stimulate research.
—old—
The easiest way of attacking an isolated TEE workload is by running malicious software on the machine as this doesn’t require physical access to a machine. Spectre is a classic example of such an attack, but there have been many examples.
In talking about future architectures, we’ve mostly talked about the low hanging fruit of better hardware isolation. Most of these attacks exploit the fact that attacker code and target code share the same processor and memory hierarchy, so if we simply assign sensitive workloads to their own processor, many of these attacks become hard to pull off. This approach is already in use in production (e.g. Bonkbot’s architecture).
However, its unclear how far we can take this approach. Some use cases may make it very hard to separate “trusted” and “untrusted code” in this way. Take this use case for example (diagram below). The idea is to attest to running an environment (think container engine) and allowing some untrusted actor to deploy non-public code to this environment. The importance of the attested environment is that it imposes constraints on the untrusted code. In this specific example, the environment imposes logging delays for privacy, but perhaps there are other constraints that we would want to impose.
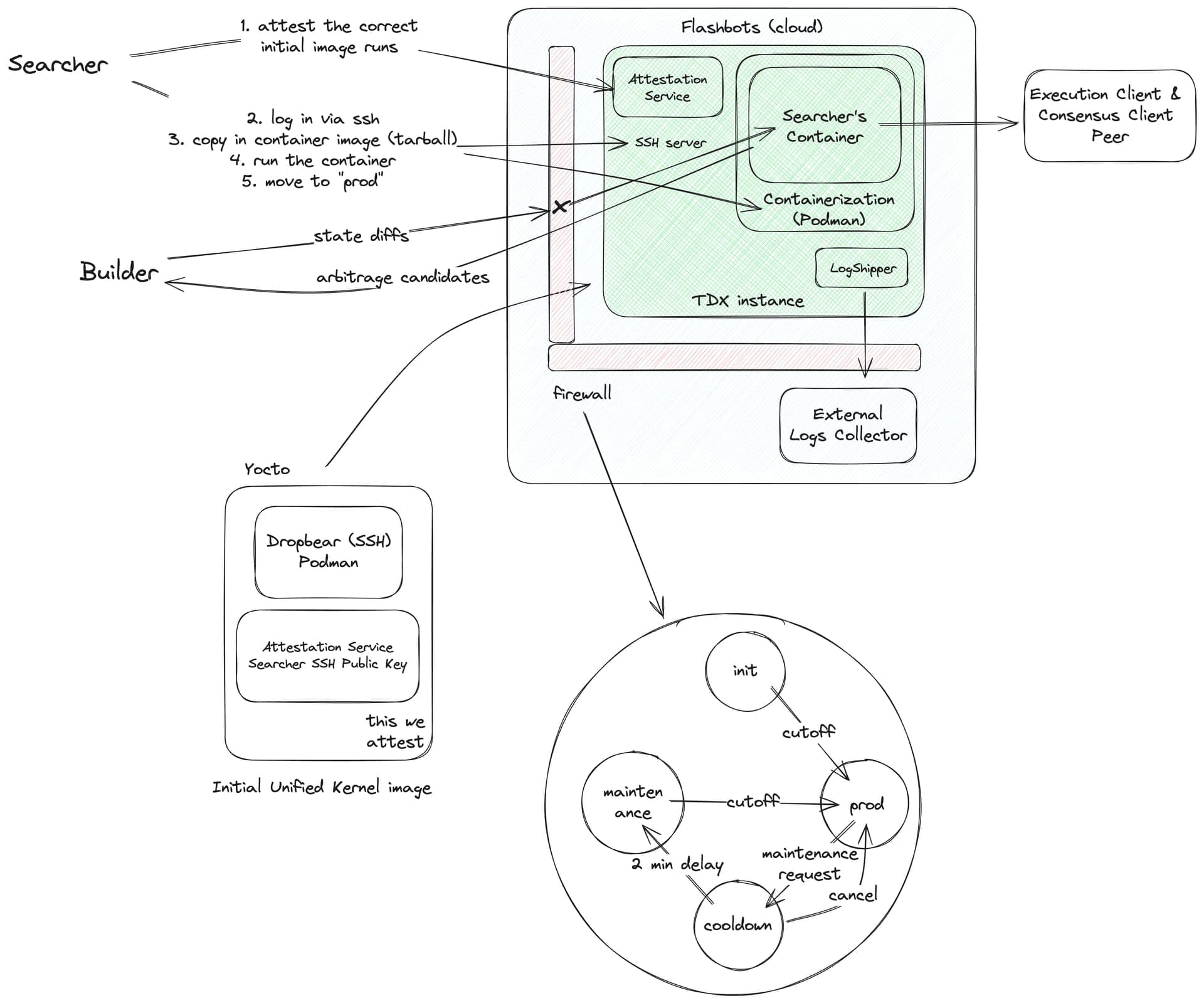
We could perhaps enforce this kind of delay at the hardware level. One core runs the “environment” which imposes the delay and the other core runs the untrusted code, but we are able to attest that all outputs from the untrusted core are piped via the “environment.”
Questions:
- What other constraints could we reasonably want to impose? E.g. ephemerality (no persistent state between runs), or compute limitations (clock cycles or “gas”) - what else?
- Can we impose these constraints at a hardware level to avoid having to run “trusted” and “untrusted” code on the same processor?
- Under what conditions are we comfortable sharing a processor? E.g. EVM and EVM transactions fit into this model and we seem fine with it. If the “environment” doesn’t contain any secrets then maybe we can bound the worst case to a violation of constraints?
- If we are going for a shared processor model, what do we want to do at the processor level to allow for the appropriate isolation? Do RISC-V standards like PMP make us happy?
Note: I’ve been talking about a binary “hardware enforced” and “software enforced” world, but in reality there’s always going to be some firmware in the TCB, but ideally we can minimise the amount of sensitive logic that cohabitates with dangerous programs